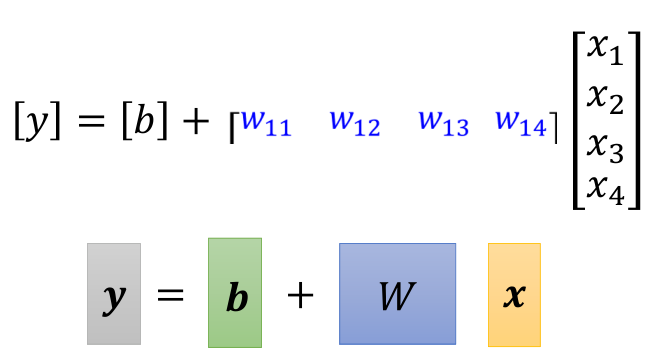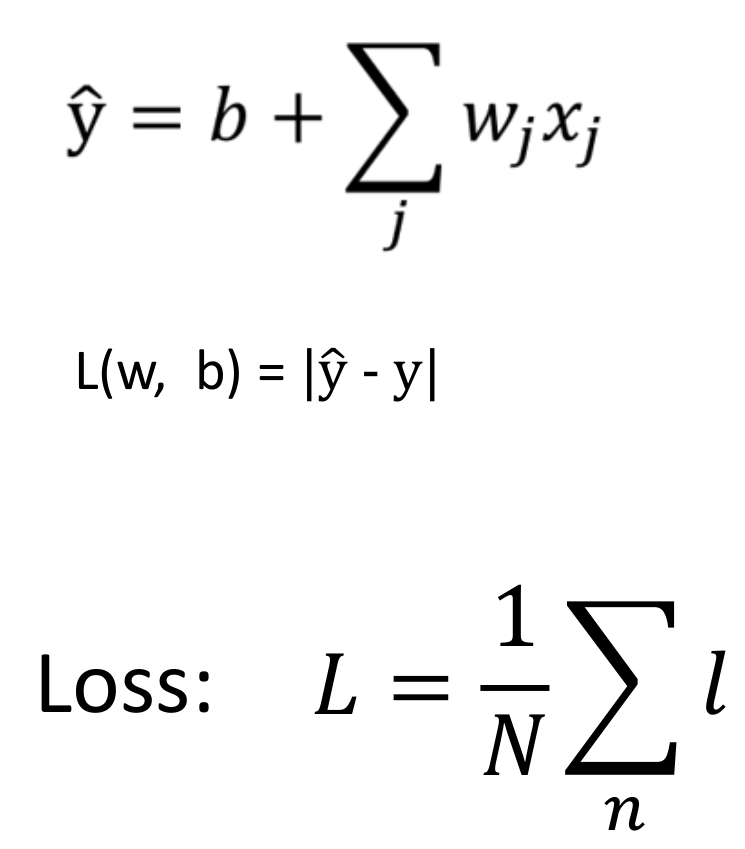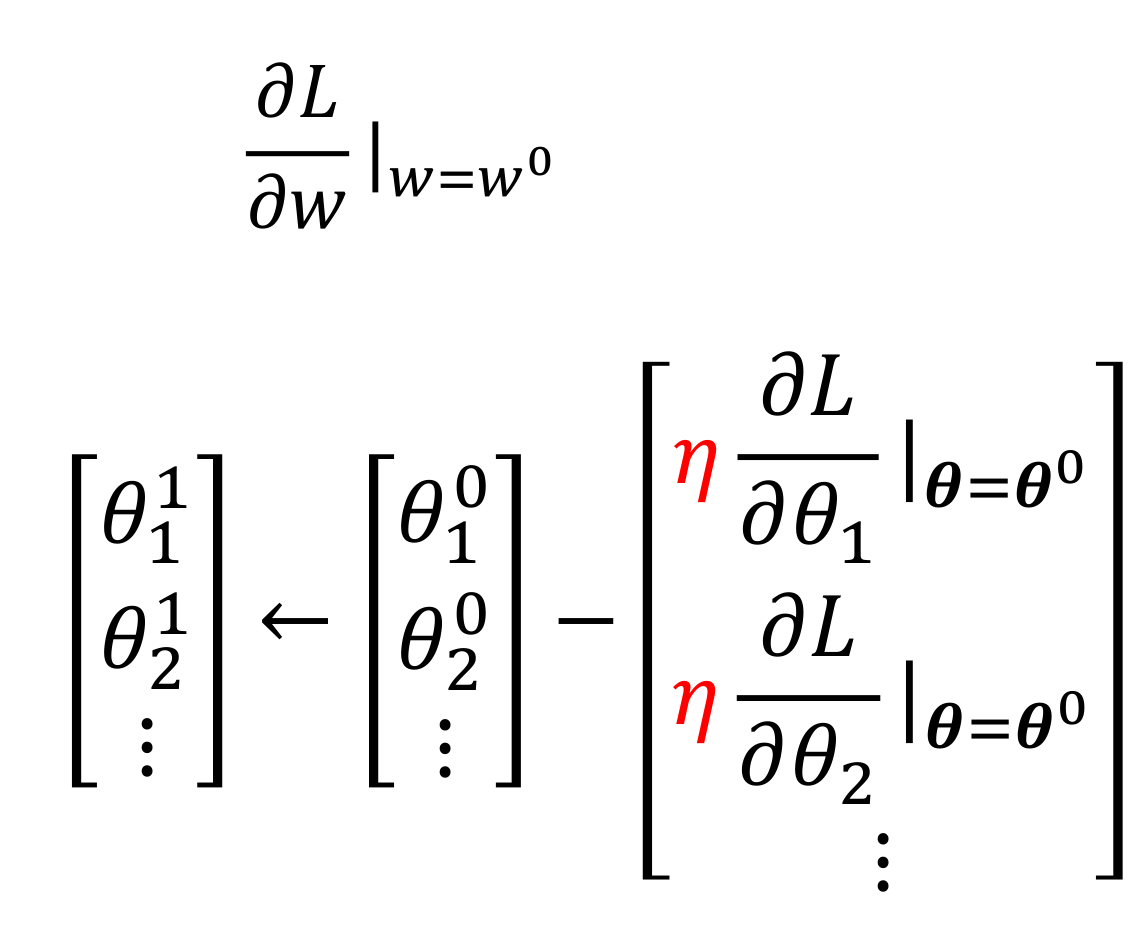lr: 超参数,学习率 w_0, b_0:初始值 requires_grad = True:A tensor can be created with requires_grad=True so that torch.autograd records operations on them for automatic differentiation. Each tensor has an associated torch.Storage, which holds its data. epochs: 定义了执行梯度下降算法的轮数
1 2 3 4 5 6 7 8 9 10 11 12 13
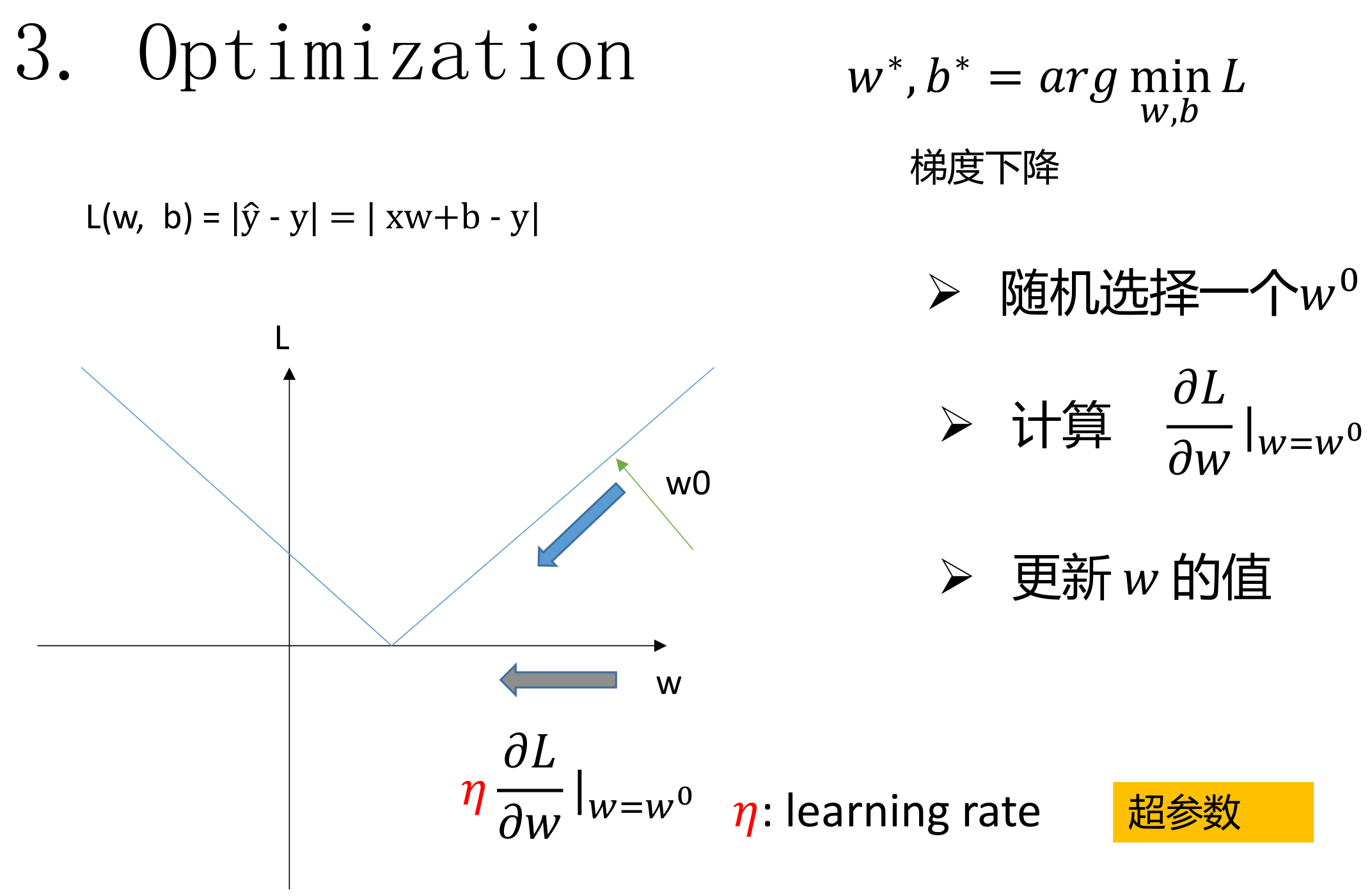
for epoch inrange(epochs): data_loss = 0 for batch_x, batch_y in data_provider(X, Y, batchsize): pred_y = fun(batch_x, w_0, b_0) loss = maeLoss(pred_y, batch_y) loss.backward() sgd([w_0, b_0], lr) data_loss += loss print("epoch %03d: loss: %.6f"%(epoch, data_loss)) print("真实的函数值是", true_w, true_b) print("深度学习得到的函数值是", w_0, b_0)
from 66 to 78 data_loss变量:统计每一轮深度学习的效果 torch.backward():深度学习python库 当调用 loss.backward() 时:
系统会计算损失值对 w_0 的 每个元素 的偏导数
最终 w_0.grad 也会是一个形状为 (4,) 的张量
part.4 函数定义
data_provider()函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14
defdata_provider(data, label, batchsize): length = len(label) indices = list(range(length)) random.shuffle(indices) for each inrange(0, length, batchsize): get_indices = indices[each: each + batchsize] get_data = data[get_indices] get_label = label[get_indices] yield get_data, get_label batchsize = 16
from 26 to 36 以下是 data_provider() 函数的逐行代码解读:
函数定义
1
defdata_provider(data, label, batchsize):
输入参数:
data: 特征数据张量(形状通常为 [样本数, 特征维度])
label: 标签数据张量(形状为 [样本数])
batchsize: 每个批次的样本数量
功能:生成随机小批量(mini-batch)数据
步骤分解
1. 获取数据集长度
1
length = len(label) # 获取总样本数(假设数据与标签一一对应)
关键作用:确定需要处理的总样本数量
潜在风险:如果 data 和 label 长度不一致会引发错误,但代码未做检查
2. 创建索引列表
1
indices = list(range(length)) # 生成顺序索引 [0, 1, 2, ..., length-1]